背景
今天刚回到家,就接到应用给我打电话,说MySQL中的一张表被锁了,让我帮他解锁下。我一想发生锁了,肯定是某个业务没有及时提交或者有人做了修改没提交。于是我让他把表名以及SQL发给我,我好排除
处理过程
收到应用发过来的SQL,查看后发现是一条update语句,本能的我去查看MySQL中是否有相关的锁等待:
select trx_mysql_thread_id from `information_schema`.`INNODB_TRX` where trx_id in (select blocking_trx_id from `information_schema`.`innodb_lock_waits`)\G
并没有发现被堵塞的会话。然后我将innodb的status 的状态以及process 输出到文件中
mysql -e "show engine innodb status\G" > /tmp/innodb.log mysql -e "show processlist" > /tmp/processlist
查看innodb status的时候发现最近也没有死锁,然后我拉到最后面,不看不知道,一看吓一跳
-------------- ROW OPERATIONS -------------- 8 queries inside InnoDB, 934 queries in queue 63 read views open inside InnoDB Main thread process no. 9045, id 140552469030656, state: sleeping Number of rows inserted 1405689533, updated 2174378506, deleted 1850571936, read 4780412837263 9.48 inserts/s, 29.91 updates/s, 0.00 deletes/s, 712443.02 reads/s
我们发现934 queries in queue,说明大量的SQL在等待进入innodb引擎。
查看innodb status中各个事务的状态,结果如下:
grep TRANSACTION /tmp/innodb.log | awk -F "," '{print $2}' | sort | uniq -c |sort -n
1 ACTIVE 0 sec inserting
1 ACTIVE 107 sec sleeping before entering InnoDB
1 ACTIVE 109 sec sleeping before entering InnoDB
1 ACTIVE 111 sec sleeping before entering InnoDB
1 ACTIVE 111 sec starting index read
1 ACTIVE 112 sec sleeping before entering InnoDB
1 ACTIVE 118 sec sleeping before entering InnoDB
1 ACTIVE 11 sec starting index read
1 ACTIVE 125 sec sleeping before entering InnoDB
1 ACTIVE 131 sec sleeping before entering InnoDB
1 ACTIVE 132 sec sleeping before entering InnoDB
1 ACTIVE 144 sec sleeping before entering InnoDB
1 ACTIVE 146 sec sleeping before entering InnoDB
1 ACTIVE 14 sec fetching rows
1 ACTIVE 14 sec sleeping before entering InnoDB
1 ACTIVE 153 sec sleeping before entering InnoDB
1 ACTIVE 157 sec sleeping before entering InnoDB
1 ACTIVE 158 sec sleeping before entering InnoDB
1 ACTIVE 15 sec fetching rows
1 ACTIVE 15 sec starting index read
1 ACTIVE 166 sec sleeping before entering InnoDB
1 ACTIVE 168 sec sleeping before entering InnoDB
1 ACTIVE 183 sec sleeping before entering InnoDB
1 ACTIVE 18 sec sleeping before entering InnoDB
1 ACTIVE 205 sec sleeping before entering InnoDB
1 ACTIVE 249 sec sleeping before entering InnoDB
1 ACTIVE 255 sec sleeping before entering InnoDB
1 ACTIVE 276 sec sleeping before entering InnoDB
1 ACTIVE 280 sec sleeping before entering InnoDB
1 ACTIVE 282 sec sleeping before entering InnoDB
1 ACTIVE 286 sec sleeping before entering InnoDB
1 ACTIVE 28 sec sleeping before entering InnoDB
1 ACTIVE 298 sec sleeping before entering InnoDB
1 ACTIVE 30 sec sleeping before entering InnoDB
1 ACTIVE 33 sec sleeping before entering InnoDB
1 ACTIVE 40 sec sleeping before entering InnoDB
1 ACTIVE 43 sec starting index read
1 ACTIVE 45 sec starting index read
1 ACTIVE 47 sec starting index read
1 ACTIVE 52 sec sleeping before entering InnoDB
1 ACTIVE 5 sec fetching rows
1 ACTIVE 5 sec starting index read
1 ACTIVE 62 sec sleeping before entering InnoDB
1 ACTIVE 64 sec sleeping before entering InnoDB
1 ACTIVE 76 sec sleeping before entering InnoDB
1 ACTIVE 7 sec sleeping before entering InnoDB
1 ACTIVE 7 sec starting index read
1 ACTIVE 807 sec sleeping before entering InnoDB
1 ACTIVE 88 sec sleeping before entering InnoDB
1 ACTIVE 89 sec sleeping before entering InnoDB
1 ACTIVE 8 sec sleeping before entering InnoDB
1 ACTIVE 92 sec sleeping before entering InnoDB
1 ACTIVE 95 sec sleeping before entering InnoDB
1 ACTIVE 96 sec sleeping before entering InnoDB
1 ACTIVE 97 sec sleeping before entering InnoDB
2 ACTIVE 108 sec sleeping before entering InnoDB
2 ACTIVE 10 sec starting index read
2 ACTIVE 130 sec sleeping before entering InnoDB
2 ACTIVE 151 sec sleeping before entering InnoDB
2 ACTIVE 154 sec sleeping before entering InnoDB
2 ACTIVE 16 sec sleeping before entering InnoDB
2 ACTIVE 190 sec sleeping before entering InnoDB
2 ACTIVE 194 sec sleeping before entering InnoDB
2 ACTIVE 196 sec sleeping before entering InnoDB
2 ACTIVE 19 sec sleeping before entering InnoDB
2 ACTIVE 200 sec sleeping before entering InnoDB
2 ACTIVE 21 sec sleeping before entering InnoDB
2 ACTIVE 29 sec sleeping before entering InnoDB
2 ACTIVE 45 sec sleeping before entering InnoDB
2 ACTIVE 57 sec sleeping before entering InnoDB
3 ACTIVE 214 sec sleeping before entering InnoDB
3 ACTIVE 53 sec sleeping before entering InnoDB
5 ACTIVE 11 sec sleeping before entering InnoDB
5 ACTIVE 5 sec sleeping before entering InnoDB
57 not started
847 not started sleeping before entering InnoDB
同样的,也说明了innodb 大量的会话无法进入innodb。
此时,我去检查发现Linux系统的io ,cpu,发现io没有等待,cpu使用率在50%左右,尚未构成瓶颈。
该机器为24个CPU,查看innodb_thread_concurrency参数,发现该参数为8。本来该机器是作为备端的,后来该虚机扩过CPU,但是该参数还是原来的8。和应用说明需要修改参数,看能不能重启。应用反馈说该业务不是核心业务,可以重启,时间在5分钟内。于是立马着手准备开干,修改参数,然后重启。重启完成后,应用反馈正常,我一边观察,一边继续分析问题。
innodb_thread_concurrency:
InnoDB tries to keep the number of operating system threads concurrently inside InnoDB less than or equal to the limit given by this variable
过了一会儿,又出现大量的队列等待进去innodb,和应用沟通反馈业务响应又变慢了,立马杀了一把连接,脚本如下:
mysql -e "show processlist "| awk '{print $1}' | grep -i -v id | awk '{print "kill "$1 ";"}' | mysql
业务反馈已经正常,赶紧快马加鞭的分析问题。
虽然已经扩大了能够进入innodb的阀值,但是还是发生堵塞,说明根源还没有解决。
A thread is placed in a queue when it tries to enter InnoDB if the number of threads has already reached the concurrency limit.
With a large innodb_concurrency_tickets value, large transactions spend less time waiting for a position at the end of the queue (controlled by innodb_thread_concurrency) and more time retrieving rows
从官方文档中,我们可以发现,一旦innodb 内部的线程达到了innodb_thread_concurrency的设置,其他的线程就在队列中等待。
对于线程来说,如果没有ticket,那么将需要在队列中等待,一旦能够进入innodb,他将拿到innodb_concurrency_tickets张数的票,此后进入Innodb,将不需要再排队,直到tickets被消耗完。
所以,对于线程来说,他如果已经拿到了ticket,且已经进入了innodb内部,那么SQL执行越慢,在innodb内部呆的时间越久,那么其他本来执行时间是几毫秒的SQL都需要等待漫长的时间,然后才能进入innodb内部去执行。
我们通过一个图来理解下这个过程:
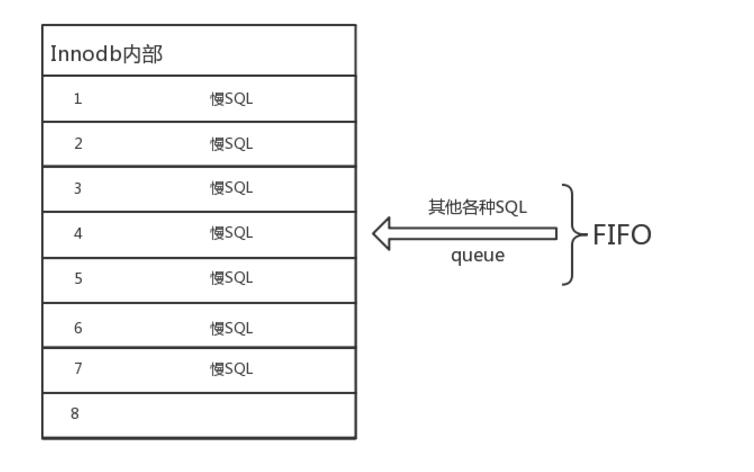
原先的环境中innodb_thread_concurrency为8,所以在innodb内部一共有8个位置,可以并发执行8个线程,如果8个位置中都有线程正在执行,那么其他线程需要在后面的FIFO队列中等待。
打个比方,医院有总共有8个手术室,各个手术室可以自己独立做手术,彼此不干扰。一个手术室一个时间点只能对一个人做手术,除了手术室,其他地方不能做手术。
如果8个手术室都有人在做手术,那么其他在该医院需要等待做手术的人就需要等待,并且需要遵守先来先做的规则(我们不考虑特别紧急的手术)
有的手术做的比较快,有的做的比较慢。
如果一个手术室手术完毕,那么后面排的第一个人可以进入做手术。
如果8个手术室都在做时间很久的手术,那么即使后面只需要1个小时的手术,也是要等待前面有手术室空出来。
理解了这一点,我们就好理解为什么有那么多长的线程在等待在队列上了,很明显,肯定是那些慢SQL嘛!
我们继续分析当时的session 快照。
cat /tmp/process.log | sed '2,$p' | awk -F "\t" '{print $7"\t"$8}' | grep -v NULL | sort | uniq -c | sort -n
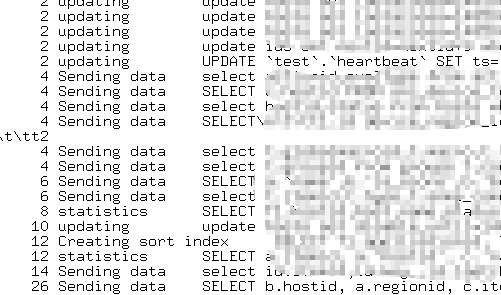
我们发现在session中,存在大量的select类型的SQL,其中一条SQL出现频率较高,存在怀疑
SELECT b.hostid, a.regionid, c.itemid, d.`host`, d.`name` FROM xx a, xx b, xx c, xxx d WHERE a.id = b.dtr_id AND c.hostid = b.hostid AND d.hostid = b.hostid AND b.hostid in (select DISTINCT(a.hostid) from items a,items_score b where a.itemid=b.itemid and a.status=0 and b.is_score=0) AND c.eventstatus 0 AND a.regionid =11
但是我们也无法确定根源是这条SQL,因为就目前的情况来看,如果存在执行频率较高,且效率很高的SQL,那么也是会被堵塞在进入innodb的队列中。
同时在session中,竟然发现hearbeat表的更新,这张表示是pt-hearbeat用来监控主备延迟用的,每秒更新一次,表里面就只有一条记录,按理说更新应该非常快。多次check processlist,发现该更新hearbeat表的SQL执行了将近10秒,可见,该MySQL数据库的响应是多么的缓慢。
我们要从innodb status中去分析到底哪个SQL占据了innodb内部,导致其他SQL无法进入。
awk 'BEGIN{RS="---TRANSACTION";ORS="---TRANSACTION";}{if(!match($0,"BACKGROUND THREAD")&&match($0,"inside InnoDB"))print $0}' /tmp/innodb.log | more

我们可以发现,innodb内都是我们刚刚怀疑的那个SQL。取出该SQL,我们查看其执行计划:
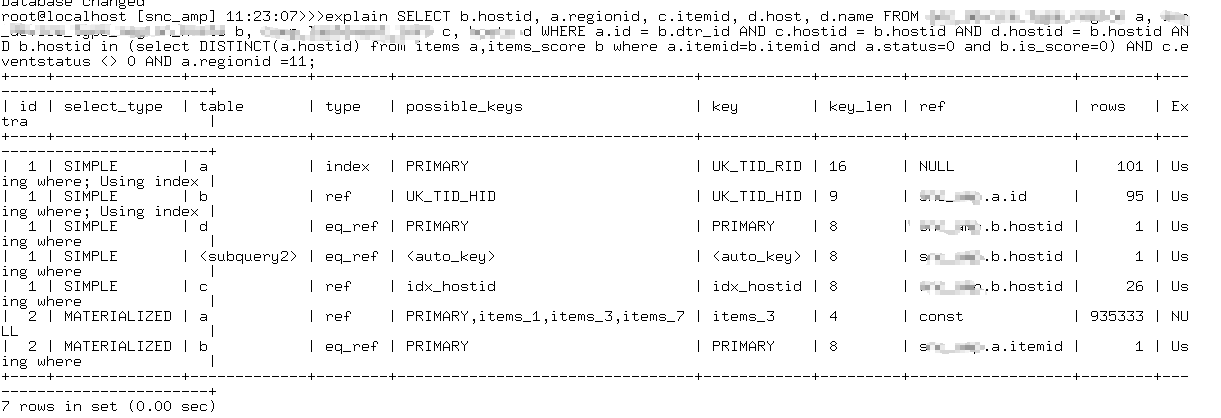
发现该SQL在执行计划的一步中扫描了90w行的记录。
我们去抓取了慢日志,利用pt-query-digest 分析2017-01-22日从19:00:00开始的慢日志:

我们发现在1个半小时不到的时间内,该SQL执行了600多次,扫描的行特别多,数据量较大,执行时长分布在10秒以上,95%的SQL执行时长达到了285秒。
赶紧将SQL发给应用查看,让他优化逻辑,减少扫描行数,观察了一会儿,数据库恢复稳定。
总结
其实很多情况下,数据库出现问题都是出现了劣质SQL,我们需要准备好相应的脚本,在关键时刻,快而准的找到那条致命的SQL。
参考文档:
1、[InnoDB系列] — SHOW INNODB STATUS 探秘
2、innodb_concurrency_tickets
3、与INNODB thread有关的三个参数

我日 大半夜查问题 居然查到你这了
可以可以,大哥欢迎再次光临
看起来思路是没有问题的,
但是没有分析到问题的细节 ,为什么一条 select 查询会导致update 花费10s左右,为什么有些事务 耗费了100多秒?
可以把更详细的因果关系 写出来
恩,昨晚分析完记录笔记比较匆忙,今天又重新整理了下。
最终是定位到这条SQL执行次数过多,这个SQL堵在innodb内部?堵在里面的全是这一条sql?
是的,在innodb内部都是该SQL