1.pt-ioprofile
做数据库运维的兄弟们常常遇到这样的问题,iostat -x 1看到某块盘的%util为100%,老大下命令了,立刻给我降下来。其实这个时候我们是很蒙逼的,虽然知道是IO子系统不行,但是不知道从何下手,到底是数据库的那部分操作使IO这么忙,或者说到底是哪个表,哪个数据文件的IO动作最频繁,以及他到底是什么样的系统调用。
pt-ioprofile就是解救大家的神器,pt-ioprofile主要做了两件事情,1. lsof+strace每秒2.对输出结果做聚合计算。输出的内容正是我们想要的,可以帮我们清晰的定位出数据库IO问题所在。输出内容如下:
[mysql@hpc02 mysqldata1]$ pt-ioprofile
Sun Oct 23 12:03:06 CST 2016
Tracing process ID 3156
total pread read pwrite write fdatasync fsync open close lseek fcntl filename
0.859126 0.000000 0.000000 0.000000 0.000000 0.000000 0.859126 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/ib_logfile0
0.702415 0.000000 0.000000 0.062207 0.000000 0.000000 0.640208 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/ib_logfile1
0.046738 0.000000 0.000000 0.000111 0.000000 0.000000 0.046433 0.000074 0.000049 0.000000 0.000071 /data/mysqldata1/ib_814_837_trunc.log
0.045482 0.000000 0.000000 0.000000 0.000000 0.000000 0.045482 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/mysql/innodb_index_stats.ibd
0.044966 0.042028 0.000000 0.000000 0.000000 0.000000 0.002706 0.000041 0.000054 0.000108 0.000029 /data/mysqldata1/test/example3.ibd
0.021146 0.000000 0.000000 0.000000 0.000124 0.021022 0.000000 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/mysql-bin.000053
0.016022 0.015486 0.000000 0.000000 0.000000 0.000000 0.000536 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/undo001
0.005385 0.000000 0.000000 0.001927 0.000000 0.000000 0.003458 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/xb_doublewrite
0.002102 0.000000 0.000000 0.000000 0.000000 0.000000 0.002102 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/ibdata1
0.000714 0.000000 0.000000 0.000000 0.000000 0.000000 0.000714 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/mysql/innodb_table_stats.ibd
0.000612 0.000000 0.000000 0.000000 0.000000 0.000000 0.000612 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/undo002
0.000500 0.000050 0.000184 0.000000 0.000000 0.000000 0.000000 0.000076 0.000064 0.000126 0.000000 /data/mysqldata1/test/example3.frm
0.000096 0.000000 0.000052 0.000000 0.000000 0.000000 0.000000 0.000028 0.000016 0.000000 0.000000 /dev/urandom
0.000092 0.000000 0.000000 0.000000 0.000092 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 /data/mysqldata1/mysql_general.log
是不是很棒,列表中的数字的单位都是时间s(后面给大家介绍其他输出单位)。这些输出都是底层系统调用,我们一列一列的来看。
total:该列是对后面所有列相加得到的和。
read/write:read系统调用从文件描述符fd所代指的打开文件中读取/写入数据,通常会配合lseek系统调用来使用,首先使用lseek来定位偏移量,然后进行read/write操作。
ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, void *buf, size_t count);
pread/pwrite:
ssize_t pread(int fd, void *buf, size_t count, off_t offset); ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
该系统调用让我们在fd文件的offset处开始读取/写入,读取count个字节,并将这些数据放入*buf中,但是不改变文件文件的当前偏移量。 那么pread和read,pwrite和write有何区别呢?
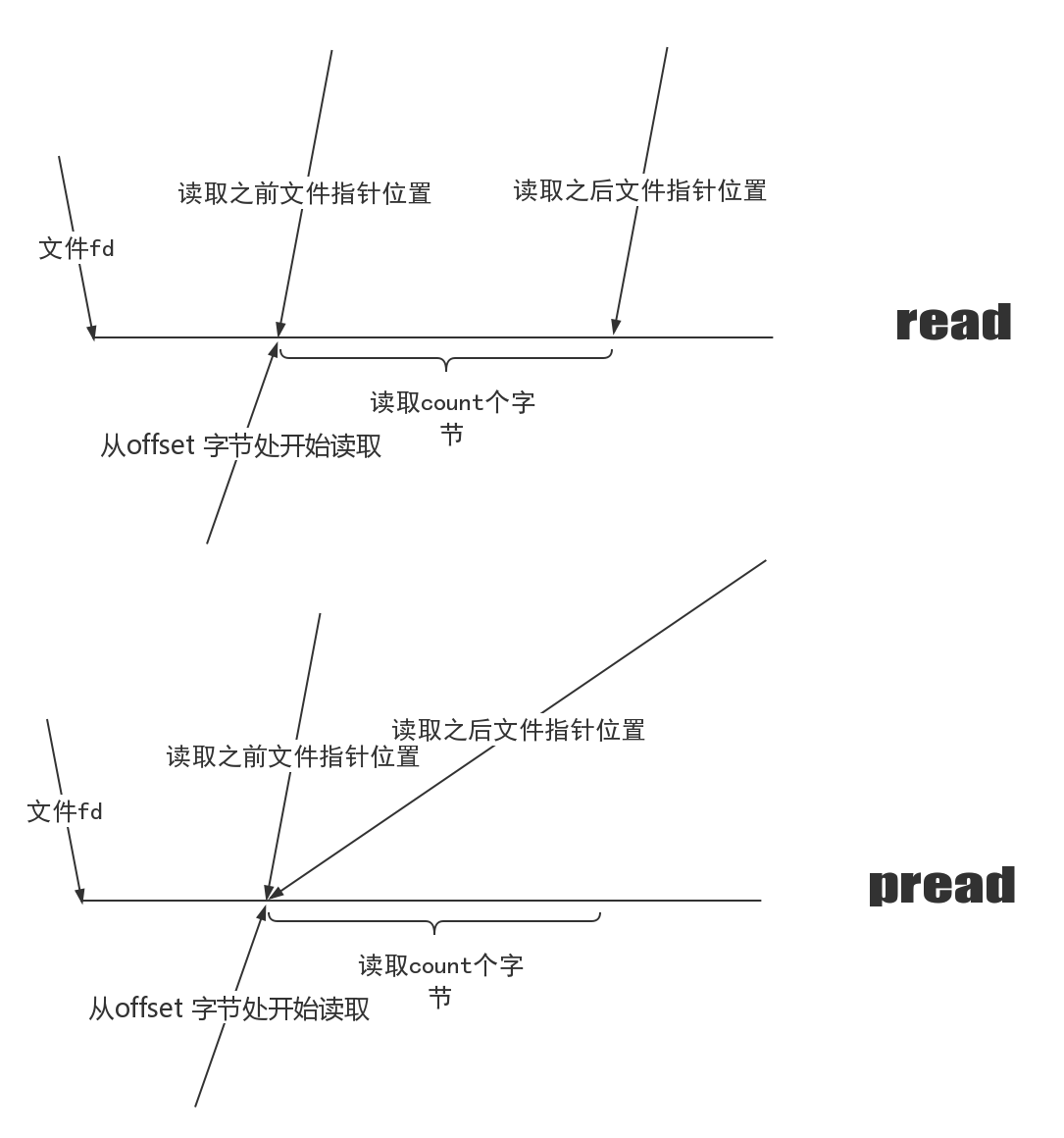
上图中我们假设文件偏移量刚开始敲好就在offset处,也就是说pread不改变文件原由的偏移量。那么write和pwrite的区别也是类似的,pwrite主要使用在多线程并发读写文件的场景,多个线程同时读写文件彼此不受影响。
fdatasync /fsync:
1.fsync=数据+元数据(属主,属组,文件权限文件大小,文件链接)
#include
int fsync(int fd);
fsync的功能是确保文件fd所有已修改的内容已经正确同步到硬盘上,该调用会阻塞等待直到设备报告IO完成。
除了同步文件的修改内容(脏页),fsync还会同步文件的描述信息(metadata,包括size、访问时间st_atime & st_mtime等等),因为文件的数据和metadata通常存在硬盘的不同地方,因此fsync至少需要两次IO写操作,变向随机IO.2.fdatasync=数据
fdatasync,放宽了同步的语义以提高性能:
#include
int fdatasync(int fd);
fdatasync的功能与fsync类似,但是仅仅在必要的情况下才会同步metadata,因此可以减少一次IO写操作。举例来说,文件的尺寸 (st_size)如果变化,是需要立即同步的,否则OS一旦崩溃,即使文件的数据部分已同步,由于metadata没有同步,依然读不到修改的内容。而最后访问时间(atime)/修改时间(mtime)是不需要每次都同步的,只要应用程序对这两个时间戳没有苛刻的要求,基本无伤大雅。
open/lose/seek:这是最基本的三种文件系统调用,分别是openda打开文件描述符,close是关闭文件描述符,lseek是改变文件偏移量。这里不再赘述,毕竟不是讲系统编程.
fcntl:函数可以改变已打开的文件性质,较复杂,有兴趣可自行研究。
filename:对应的数据文件。
根据以上采集的信息,我们可以很快分析出数据库到底在哪部分造成了IO子系统瓶颈
2.常用配置
1.60s内数据库有IO活动的文件产生的各种系统调用次数
[ampmon@vq23ucmd02 ~]$ pt-ioprofile --profile-process=mysqld --run-time=60 --save-samples=/app/ampmon/mysql_ioprofile.txt --group-by=filename --cell=count --aggregate=sum
Sun Oct 23 14:14:33 CST 2016
Tracing process ID 16676
total pread read pwrite write fsync lseek ftruncate filename
23164 0 0 0 11581 2 11581 0 /data/smp/mysql/data/master.info
19917 0 3949 0 12018 1 3949 0 /data/smp/mysql/data/vq23ucmd02-relay-bin.000063
3755 0 230 0 267 0 3173 85 /tmp/ML23MkEh
2459 0 0 0 2459 0 0 0 /data/smp/mysql/data/mysql-bin.000021
1667 0 0 1605 0 62 0 0 /data/smp/mysql/data/ib_logfile2
659 0 0 327 0 332 0 0 /data/smp/mysql/data/ibdata1
183 2 0 0 0 181 0 0 /data/smp/mysql/data/snc_amp/trends_uint.ibd
171 3 0 0 0 168 0 0 /data/smp/mysql/data/snc_amp/history_uint.ibd
121 0 0 0 0 121 0 0 /data/smp/mysql/data/snc_amp/history_str.ibd
17 1 0 0 0 16 0 0 /data/smp/mysql/data/snc_amp/history.ibd
15 0 0 0 0 15 0 0 /data/smp/mysql/data/snc_amp/events.ibd
14 0 0 0 0 14 0 0 /data/smp/mysql/data/snc_amp/trends.ibd
8 0 0 0 0 8 0 0 /data/smp/mysql/data/ib_logfile0
7 0 0 0 0 7 0 0 /data/smp/mysql/data/snc_amp/item_discovery.ibd
5 0 0 0 0 5 0 0 /data/smp/mysql/data/snc_amp/last_uint.ibd
2 0 0 0 0 2 0 0 /data/smp/mysql/data/snc_amp/last.ibd
2 0 0 0 0 2 0 0 /data/smp/mysql/data/snc_amp/items.ibd
1 0 0 0 0 1 0 0 /data/smp/mysql/data/snc_amp/last_str.ibd
1 0 0 0 0 1 0 0 /data/smp/mysql/data/snc_amp/hosts.ibd
2.60s内数据库中有IO活动的文件,各种系统调用平均每秒产生的数据量
[ampmon@vq23ucmd02 ~]$ pt-ioprofile --profile-process=mysqld --run-time=60 --save-samples=/app/ampmon/mysql_ioprofile.txt --group-by=filename --cell=sizes --aggregate=avg
Sun Oct 23 14:11:15 CST 2016
Tracing process ID 16676
total pread read pwrite write fsync lseek ftruncate filename
115511329 0 3711 0 771 0 786756564 0 /data/smp/mysql/data/vq23ucmd02-relay-bin.000063
16384 16384 0 0 0 0 0 0 /data/smp/mysql/data/snc_amp/history_uint.ibd
16384 16384 0 0 0 0 0 0 /data/smp/mysql/data/snc_amp/history.ibd
16384 16384 0 0 0 0 0 0 /data/smp/mysql/data/snc_amp/events.ibd
13803 0 0 14444 0 0 0 0 /data/smp/mysql/data/ib_logfile2
6501 0 26136 0 23221 0 3201 0 /tmp/ML23MkEh
3816 0 0 0 3816 0 0 0 /data/smp/mysql/data/mysql-bin.000021
64 0 0 0 130 0 0 0 /data/smp/mysql/data/master.info
以上两份信息我是从一个生产库的备库上采集的, 很显然,现在relay-log是系统中IO消耗最大部分。
更多组合请自行研究,解释下参数:
–aggregate:sum|avg。可以算平均值和总和
–cell:count|sizes:times。可以算系统调用次数,系统调用传输数据量,系统调用耗费的时间
–group-by:all|filename|pid。聚合方式,所有聚合在一起还是按照文件聚合
–profile-process:mysqld进程名
–run-time:采集时间
–save-samples:将输出保存到文件,供后续分析。

近期评论